
Após começar a enviar dados do RD Station para o seu data warehouse, será necessário modelar os dados para que fiquem facilmente consultáveis.
Isso porque o Webhook do RD Station envia os dados das conversões em formato JSON para o seu banco de dados. JSON é uma abreviação para Javascript Object Notification e é um formato de troca de informações através de texto.
Exemplificando, ao consultar a sua tabela do RD no seu data warehouse, você irá se deparar com uma estrutura parecida com essa:

No exemplo acima, o campo "body" traz as informações do lead, como nome, e-mail, id, data de criação, primeira e última conversão e campos customizados que você pode ter configurado dentro da sua ferramenta. Na forma que está, será difícil pesquisar algumas dessas informações para compor as suas métricas e indicadores pois todos os dados estão condensados num campo de texto. Porém com um pouquinho de SQL é muito simples transformar essa grande linha de dados em várias colunas diferentes, cada uma com a sua propriedade.
1. Para começar, é importante entender a hierarquia dos campos dentro do JSON, para isso, copie o texto do campo "body" de algum dos registros, e vá em um JSON Parser, um site que "desmonta" o JSON e deixa-o mais compreensível a "olho nu". No exemplo abaixo, todos os dados ficam abaixo da propriedade "leads", as propriedades com um sinal de "+" ou "-" ao lado, mostram que existem outros campos abaixo delas.
Exemplo: Para extrair o campo "identificador" da propriedade "first conversion" (primeira conversão), a hierarquia é leads > first_conversion > content > identificador.

2. Agora que você já entendeu a estrutura do JSON, crie um modelo dentro da plataforma da Kondado para começar a escrever a sua query em SQL. O tutorial de como fazer isso pode ser encontrado clicando aqui.
3. A sintaxe do seu SQL irá depender do tipo do seu banco de dados, os exemplos que trazemos abaixo são do PostgreSQL e BigQuery, respectivamente. Neles, estamos extraindo os campos de id do lead, nome, e-mail, data da primeira conversão, identificador e data de última conversão.
Sintaxe do PostgreSQL:
SELECT trim('"' FROM (json_array_elements((body::json)->'leads')->'id')::text) as id_lead,
trim('"' FROM (json_array_elements((body::json)->'leads')->'name')::text) as nome,
trim('"' FROM (json_array_elements((body::json)->'leads')->'email')::text) as email,
trim('"' FROM (json_array_elements((body::json)->'leads')->'first_conversion'-> 'created_at')::text) as primeira_conversao,
trim('"' FROM (json_array_elements((body::json)->'leads')->'first_conversion'-> 'content' -> 'identificador')::text) as identificador,
trim('"' FROM (json_array_elements((body::json)->'leads')->'last_conversion'-> 'created_at')::text) as ultima_conversao
FROM webhook_rdstation
Para entender a estrutura do código:
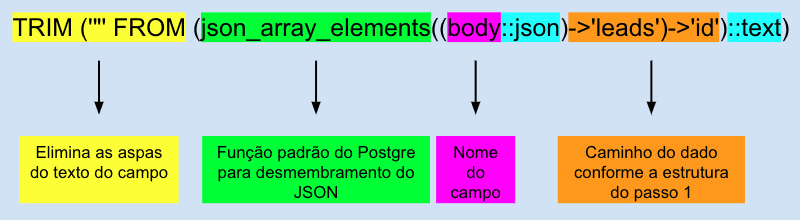
Sintaxe do BigQuery:
SELECT REPLACE(JSON_EXTRACT(body, '$[leads][0].id'), "\"","") AS id_lead,
REPLACE(JSON_EXTRACT(body, '$[leads][0].name'), "\"","") AS nome,
REPLACE(JSON_EXTRACT(body, '$[leads][0].email'), "\"","") AS email,
CAST(REPLACE(JSON_EXTRACT(body, '$[leads][0].first_conversion.created_at'), "\"","") AS TIMESTAMP) AS primeira_conversao,
REPLACE(JSON_EXTRACT(body, '$[leads][0].first_conversion.content.identificador'), "\"","") AS identificador,
CAST(REPLACE(JSON_EXTRACT(body, '$[leads][0].last_conversion.created_at'), "\"","") AS TIMESTAMP) AS ultima_conversao
FROM `seudataset.webhook_rdstation`4. Ao salvar o seu modelo, quando ele for executado, será criada uma tabela no seu data warehouse com a seguinte estrutura:

Para incluir mais campos, basta replicar o código acima especificando o caminho deles dentro da estrutura do JSON.
Agora que o JSON foi desmembrado em vários campos, será muito mais simples consultar os dados do RD Station e criar todas as métricas e indicadores que você precisar!
Se você usa o RD Station mais ainda não envia os seus dados para o seu banco de dados, conheça a Kondado e construa integrações sem precisar desenvolver uma linha sequer de código!
Pivotar dados de leads e conversões do RD Station no data warehouse
Use SQL para extrair os campos do JSON enviado pelo webhook do RD Station e materializar uma tabela analítica via Modelo da Kondado.
Receba os dados do RD Station via webhook
Configure o conector de webhook do RD Station na Kondado e direcione o destino para seu data warehouse (PostgreSQL, BigQuery, Redshift, etc.). Os dados das conversões chegarão em uma coluna body em formato JSON.
Inspecione a estrutura do JSON
Copie o conteúdo do campo body de um registro de exemplo e cole em um JSON Parser online. Identifique a hierarquia (no exemplo, tudo fica abaixo de leads) e mapeie os caminhos dos campos que você precisa, inclusive custom fields.
Escreva a query SQL para o seu banco
No PostgreSQL, use json_array_elements(body::json -> 'leads') com trim('"' FROM …) para limpar aspas. No BigQuery, use JSON_EXTRACT(body, '$[leads][0].campo') com REPLACE e CAST para tipar os campos.
Crie um Modelo na Kondado
Dentro da plataforma, crie um Modelo, cole sua query e defina os acionadores. A Kondado materializa o resultado como uma tabela no destino e atualiza automaticamente toda vez que novos dados chegarem ao webhook.
Consulte e visualize os dados pivotados
Com o JSON desmembrado em colunas (id_lead, nome, email, primeira_conversao, etc.), conecte sua ferramenta de BI favorita ao banco e construa dashboards de leads e conversões.
Perguntas frequentes
json_array_elements com body::json e trim('"' FROM ...) para extrair e limpar os valores. No BigQuery, usa-se JSON_EXTRACT(body, '$[leads][0].campo') com REPLACE para remover aspas e CAST para converter timestamps. Ambos desmembram o mesmo JSON, mas com funções nativas de cada banco. Veja mais sobre destinos de dados suportados.