Derivado da palavra "humongous" (em inglês: algo maior que gigantesco), o MongoDB é um dos bancos de dados não relacionais (nosql) mais utilizados no mundo. Grande parte desse sucesso deve-se ao fato de, além da versão open source, a empresa por trás do Mongo oferecer também o Mongo Atlas, uma versão hospedada do banco de dados não relacional.
Lidar com bancos no-sql traz certas complicações, principalmente quando se considera que o Mongo não enforça tipagem, o que significa que cada documento (registro) de uma coleção (algo similar a uma tabela de um banco relacional) pode possuir um formato diferente, além de uma variável (similar a uma coluna) em um documento poder assumir valores diferentes do que em outro. Em um documento, a coluna "createdAt" pode assumir o valor de "2020-01-01" e em outro, "01/01/2020" ou mesmo "primeiro de janeiro de dois mil e vinte".
Além do cuidado necessário no desenvolvimento de aplicações em produção para manter um certo padrão nas collections, analisar dados advindos do mongo é algo um mais pouco complexo quando se fala de analytics e data science, já que funções básicas como soma de uma variável/coluna precisam lidar com o fato de que alguns dos documentos podem assumir valores não numéricos.
Quando desenvolvemos o nosso primeiro conector com o Mongo, era necessário muito trabalho manual de casting e normalização para uma estrutura relacional. Hoje estamos lançando uma nova versão que inclui:
- Opção de detecção automática do tipo da coluna/variável e conversão para um formato definido para que esse dado seja inserido em um banco relacional
- Normalização de documentos aninhados/nestados para as tabelas que são necessárias, mapeando o documento de uma estrutura não relacional para uma relacional
- Integração incremental, sendo possível buscar apenas os documentos novos ou atualizados de cada collection
Este conector suporta as seguintes versões do MongoDB: 2.6, 3.0, 3.2, 3.4, 3.6, 4.0, 4.2, 4.4 e 5.0
Não são suportados _ids que sejam em si outros objetos JSON - apenas são suportadas collections/views cujo _id seja do tipo ObjectId, String ou algum outro tipo simples
Adicionando o conector
Para adicionar o conector do mongo na plataforma da Kondado, você primeiro precisa permitir que os nossos IPs possam acessar o banco.
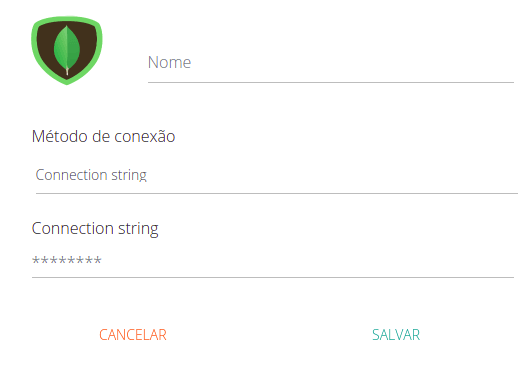
Uma vez que você liberou os nossos IPs no seu firewall, você pode adicionar as suas informações de 2 formas: parâmetros individuais ou connection string. Para selecionar entre elas, utilize o parâmetro "Método de conexão".
Caso você tenha selecione o método de conexão Connection string, você pode adicionar no campo "Connection string" a string de conexão. Alguns exemplos de strings de conexão estão abaixo. Veja mais sobre como formatar sua connection string
Exemplos de connection string:
mongodb://mongodb0.example.com:27017mongodb+srv://server.example.com/
Caso opte pelo método de conexão Parâmetros individuais, veja abaixo a descrição dos campos necessários
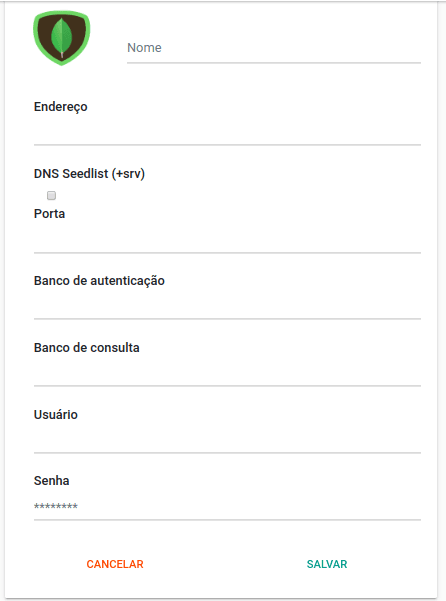
- Nome: Uma descrição interna do seu conector, por exemplo "Mongo produto"
- Endereço: IP ou DNS do seu banco ou cluster. Insira aqui apenas o endereço, sem incluir banco, porta ou parâmetros
- DNS Seedlist: Marque essa opção apenas se o seu banco utiliza seedlist para conexão (ou seja: a string de conexão dele contém "+srv"). Essa opção é bastante utilizada nos bancos MongoDB Atlas
- Porta: a porta que deve ser utilizada para a conexão (geralmente 27017).
- Banco de autenticação: apenas o nome do banco de autenticação (por exemplo: admin)
- Banco de consulta: apenas o nome do banco de consulta
- Usuário: o usuário do banco de dados
- Senha: a senha do usuário
Agora, basta criar as integrações (uma por coleção) e começar a analisar os dados do Mongo de forma relacional.
Integrações
Gráfico de relacionamento entre tabelas

Collections & Views
A nossa integração consegue obter dados não apenas de collections, mas também views.
O schema da(s) tabela(s) que serão criadas no seu banco de dados irá depender dos seguintes parâmetros:

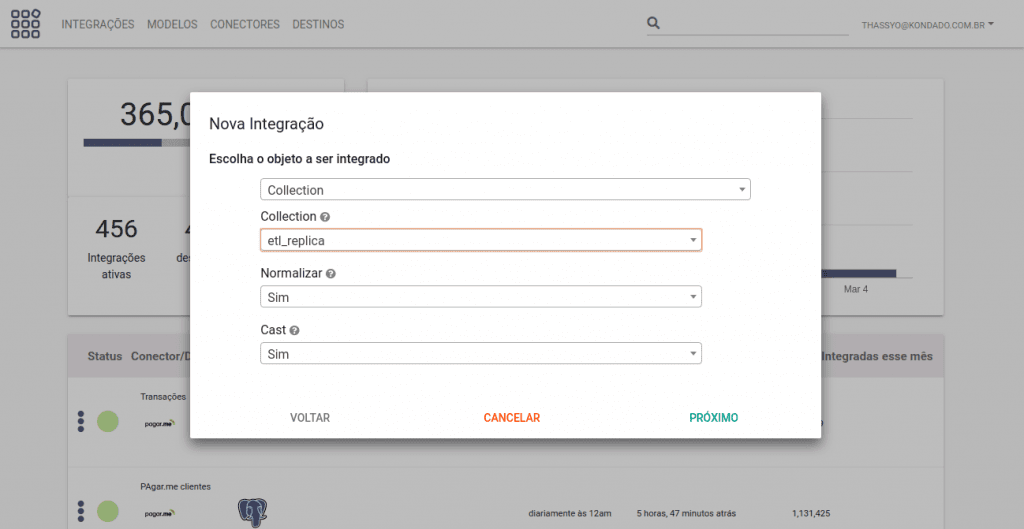
- Normalizar: Indica se, caso você possua um collection/view com documentos nestados/aninhados, deseja que seja criada uma nova tabela para este novo nível. Caso opte por não normalizar, os dados serão recepcionados em modo texto. A normalização é aplicada apenas 1 nível para baixo e os registros no segundo nível herdarão o _id dos respectivos registros de primeiro nível.
- Cast: Caso você opte por aplicação de cast, nós iremos realizar uma amostragem dos documentos da sua collection/view para determinar o tipo que cada campo deve ter no seu destino. Esta amostragem é rígida e caso todos os registros de um dado campo não sejam todos do mesmo tipo, sua coluna será criada como texto. Caso você opte por não aplicar cast, sua integração não poderá ser incremental e todos os campos serão criados e inseridos como texto.
- (Opcional) _ids de amostra de schema (separados por vírgula): Caso você possua alguns registros que estão com um schema mais completo, pode fornecê-los aqui para que sejam considerados os campos na montagem do schema final
- (Opcional) campos onde não deve ser aplicado casting (separados por vírgula): Caso você selecione Cast=Sim, você pode fornecer nomes de campos (separados por vírgula) que devem necessariamente ser escritos como text e não sofrer casting para outro tipo que pode ser confundido com o padrão deles. Isso é útil para campos que guardam números de documentos/telefones/CEPs e que apesar de se parecem com números, uma conversão para número pode alterar o seu valor - por exemplo, eliminar o 0 inicial de um CEP
As tabelas criadas, terão um formato similar ao abaixo (considerando que a tabela "nested" é uma normalização)
Objeto principal
nested
| Campo | Tipo | |
|---|---|---|
|
_id |
text |
|
|
nested_col_x">
nested_col_x |
text |
|
|
col_y">
nested_col_y |
text |
|
|
col_z">
nested_col_z |
text |
Configurar o conector MongoDB na Kondado
Guia passo a passo para integrar dados do MongoDB ao seu data warehouse, incluindo liberação de IPs, configuração de conexão e definição de parâmetros de normalização.
Liberar IPs da Kondado no firewall
Antes de começar, você precisa permitir que os IPs da Kondado acessem seu banco MongoDB. Consulte a página de segurança para obter a lista atualizada de endereços que devem ser liberados no seu firewall.
Escolher o método de conexão
Na plataforma, selecione entre "Connection string" ou "Parâmetros individuais" no campo "Método de conexão". Para MongoDB Atlas, a opção de DNS Seedlist é frequentemente necessária.
Preencher as credenciais de acesso
Informe o endereço (IP ou DNS sem porta/banco), porta (geralmente 27017), banco de autenticação, banco de consulta, usuário e senha. Se usar connection string, exemplos incluem mongodb://mongodb0.example.com:27017 ou mongodb+srv://server.example.com/.
Configurar normalização de documentos aninhados
Defina se deseja normalizar documentos nestados em tabelas separadas (apenas 1 nível) ou receber como texto. A normalização cria tabelas filhas que herdam o _id do registro pai.
Aplicar cast automático de tipos
Ative o cast para que a Kondado amostre seus documentos e defina tipos apropriados no destino relacional. Sem cast, todos os campos serão texto e a integração não poderá ser incremental. Você pode excluir campos específicos do casting, como CEPs e telefones.
Criar integrações por collection
Crie uma integração para cada collection ou view desejada. Com a integração incremental, busque apenas documentos novos ou atualizados. Conecte seus dados a destinos como data warehouses e BI tools para análise.