O S3 (Simple Storage Service) é um serviço da AWS feito para armazenamento de arquivos de forma escalável. A integração de dados do S3 para o Data Warehouse criada pela Kondado possibilita que você tenha acesso a arquivos CSV na sua nuvem analítica.
Adicionando o conector
Considere que o seu bucket chama-se nome-do-bucket-generico
Passo 1: Criar uma Nova Política IAM
- Vá para o Console IAM: https://console.aws.amazon.com/iam
- No menu à esquerda, clique em Políticas.
- Clique no botão Criar política.
- Na aba JSON, cole o seguinte documento de política
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::nome-do-bucket-generico", "arn:aws:s3:::nome-do-bucket-generico/*" ] } ] }
- Clique em Avançar: Tags, depois em Avançar: Revisar.
- No campo Nome da política, insira
S3ReadListBucketGenericoPolicy. - Clique em Criar política.
Passo 2: Criar um Novo Usuário IAM
- Vá novamente para o Console IAM: https://console.aws.amazon.com/iam
- No menu à esquerda, clique em Usuários.
- Clique em Adicionar usuário.
- Insira o nome do usuário como
S3ReadUserBucketGenerico. - Selecione Chave de acesso - Acesso programático.
- Clique em Avançar: Permissões.
Passo 3: Associar a Política ao Usuário
- Na página Permissões, clique em Anexar políticas existentes diretamente.
- Procure pela política que você criou:
S3ReadListBucketGenericoPolicy. - Marque a caixa ao lado da política e clique em Avançar: Tags, depois em Avançar: Revisar.
- Clique em Criar usuário.
Passo 4: Baixar as Chaves de Acesso
- Após criar o usuário, as ID da chave de acesso e Chave de acesso secreta serão exibidas.
- Baixe ou copie essas credenciais, pois elas não serão exibidas novamente.
Agora o usuário S3ReadUserBucketGenerico tem acesso programático para ler e listar arquivos do bucket S3 genérico.
Passo 5: Adicionar na Kondado
- Na plataforma da Kondado, clique em CRIAR + > Conector > selecione o conector do S3
- Dê um nome para o seu conector, preencha os valores obtidos no passo 4 e o nome do bucket (no nosso exemplo
nome-do-bucket-generico) onde os seus arquivos estão.
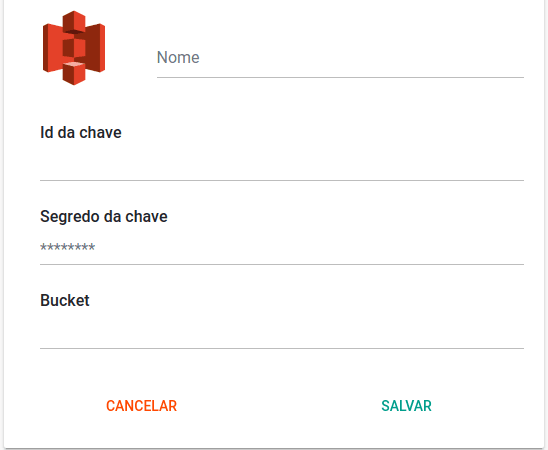
Agora basta salvar o conector e testar a conexão
Integrações
CSV
A integração para leitura de arquivos CSV irá criar uma tabela em seu destino onde todos os campos serão do tipo text e tratados para substituir caracteres especiais
Todos os arquivos devem ter cabeçalho
Os seguintes parâmetros estão disponíveis:
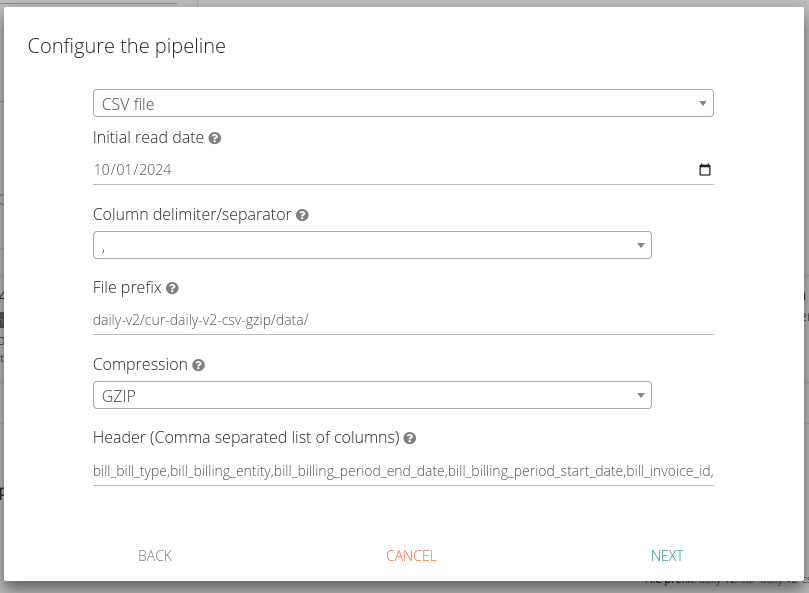
- Data inicial de leitura: Refere-se à data de modificação dos arquivos. Indica a partir de qual data os dados começarão a serem lidos. Caso escolha por deixar sua integração Integral, este parâmetro será ignorado
- Delimitador de colunas: Indique qual caracter é utilizado para separar as colunas do arquivo
- Prefixo dos arquivos: Indique qual o prefixo dos arquivos que serão inclusos, não incie com o nome do bucket ou com "/" ou "s3://". Não utilize wildcards. Exemplo pasta_x/pasta_y/inicio_do_nome_dos_arquivos_
- Compressão: Escolha GZIP caso esta seja a compressão aplicada a seus arquivos ou CSV caso não haja compressão. Ao escolher GZIP, seu arquivo deve ter extensão ".gz" ou ".gzip" e possuir apenas um arquivo dentro do ficheiro. Caso escolha CSV seu arquivo deve ter extensão ".csv"
- Header: Liste a primeira linha (cabeçalho) de seus arquivos. Não é necessário manter a ordem das colunas. Caso algum arquivo tenha campos que não estejam neste campo, estes campos serão ignorados. Caso o arquivo não possua todos os campos do header, estes campos apenas não serão lidos, sem ocasionar em falhas. Não utilize espaços entre os campos, apenas vírgulas. Por exemplo: col_x,col_y,col_z
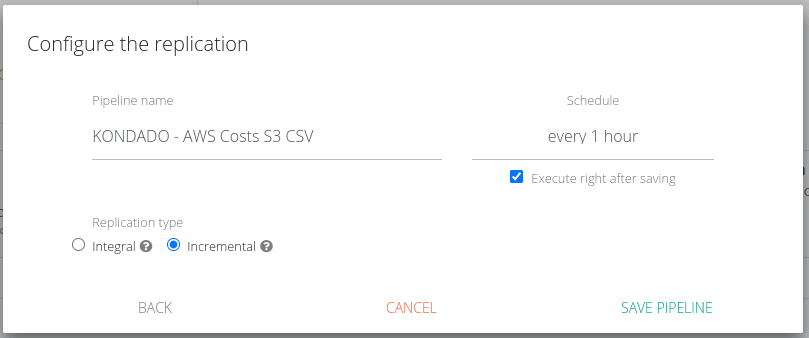
Após esta etapa, você poderá escolher o tipo de replicação de sua integração.
Caso escolha Integral, todos os arquivos que correspondem ao prefixo sempre serão lidos e caso algum arquivo seja apagado entre uma execução e outra ele também será apagado de sua tabela, o que não acontecerá caso sua replicação seja Incremental, por isso este tipo de replicação é indicada para casos em que há deleção (e não apenas alteração) de arquivos. Esta replicação pode aumentar seu número de registros
Ao escolher a replicação Incremental, sempre que um arquivo for alterado ele será alterado em seu destino, você poderá localizar o arquivo que gerou a inserção de uma dada linha e quando esta linha foi inserida/alterada pelas colunas _kdd_file_name e _kdd_insert_time, respectivamente
Integrar dados do Amazon S3 à Kondado
Configure credenciais IAM na AWS e conecte seu bucket S3 à plataforma Kondado para replicar arquivos CSV em seu Data Warehouse.
Criar política IAM de leitura no S3
No Console IAM da AWS, crie uma política JSON com as ações s3:GetObject e s3:ListBucket, apontando para o ARN do seu bucket. Nomeie-a como S3ReadListBucketGenericoPolicy e finalize a criação.
Criar usuário IAM com acesso programático
Ainda no Console IAM, adicione um novo usuário (ex: S3ReadUserBucketGenerico), selecione Chave de acesso - Acesso programático e avance para a etapa de permissões.
Anexar a política ao usuário
Na página de permissões, escolha Anexar políticas existentes diretamente, localize e marque a política criada no primeiro passo, depois conclua a criação do usuário.
Salvar as credenciais de acesso
Após criar o usuário, copie ou baixe imediatamente a ID da chave de acesso e a Chave de acesso secreta — elas não serão exibidas novamente.
Configurar o conector S3 na Kondado
Na plataforma Kondado, acione CRIAR + > Conector e selecione o conector do S3. Preencha o nome do conector, as credenciais do passo anterior e o nome do bucket, depois salve e teste a conexão.
Ajustar parâmetros de leitura de CSV e escolher replicação
Defina o delimitador, prefixo dos arquivos, compressão (GZIP ou CSV) e o cabeçalho esperado. Escolha entre replicação Integral (lê todos os arquivos sempre, reflete deleções) ou Incremental (atualiza apenas alterações, com metadados _kdd_file_name e _kdd_insert_time). Em seguida, envie os dados para seu destino.
Perguntas frequentes
s3:GetObject e s3:ListBucket em uma política IAM vinculada ao usuário de acesso programático. Essas permissões permitem listar o bucket e ler os arquivos, sem autorização para escrita ou deleção na AWS._kdd_file_name (arquivo de origem) e _kdd_insert_time (momento da inserção/alteração). Deleções no S3 não se refletem no destino neste modo..csv) ou compactados com GZIP (extensão .gz ou .gzip). Ao escolher GZIP, o arquivo deve conter apenas um arquivo CSV interno.col_x,col_y,col_z). Colunas presentes no arquivo mas ausentes do header são ignoradas; colunas do header ausentes no arquivo são lidas como vazias, sem causar falhas.