
O que é Data Munging?
Data Munging, também conhecido como pré-processamento de dados ou Data Wrangling, é o processo de limpeza, transformação e formatação de dados do seu estado bruto para uma versão padronizada que possa ser usada para análise.
Faz parte do processo de KDD (Knowledge Discovery in Databases), que já mencionamos anteriormente aqui no blog.
Começando o pré-processamento de dados
No processo de Data Munging, são empregadas várias técnicas e ferramentas. Alguns dos passos mais comuns incluem:
Limpeza de dados: Remover ou corrigir erros, duplicatas ou inconsistências nos dados.
Dados em falta: Lidar com valores ausentes através de imputação ou exclusão deles.
Transformação de dados: Converter dados em um formato ou escala adequados, como padronizar variáveis numéricas ou codificar variáveis categóricas.
Extração de características: Criar novas características ou derivar informações significativas de características existentes.
Integração de dados: Combinar vários conjuntos de dados ou fontes em um conjunto de dados unificado.
Formatação de dados: Converter dados em uma estrutura ou representação consistente.
Ferramentas
Existem diversas ferramentas e linguagens que auxiliam nesse processo, vamos falar sobre algumas delas, porém a mais popular para ciência de dados e para questões mais avançadas é a linguagem python.
Python: Python é uma linguagem de programação versátil amplamente utilizada em ciência de dados. Ela oferece diversas bibliotecas e pacotes, como Pandas e NumPy, que fornecem poderosas capacidades de manipulação e pré-processamento de dados.
O NumPy tem como foco principal fornecer operações numéricas eficientes e trabalhar com arrays multidimensionais homogêneos. Ele oferece um poderoso objeto ndarray e uma ampla gama de funções matemáticas para cálculos numéricos rápidos e eficientes. O NumPy é amplamente utilizado em computação científica, simulações numéricas e tarefas que envolvem processamento de dados numéricos em larga escala.
Por outro lado, o Pandas é construído em cima do NumPy e é projetado para lidar com dados estruturados em um formato tabular. Ele fornece um objeto de alto nível chamado DataFrame, capaz de armazenar e manipular dados bidimensionais heterogêneos. O Pandas se destaca em tarefas de limpeza de dados, pré-processamento de dados, análise exploratória de dados e manipulação de dados. Ele oferece um conjunto rico de funções e métodos para filtragem, agrupamento, mesclagem, remodelagem e análise de séries temporais.
Em resumo, o NumPy é principalmente usado para computação numérica e operações eficientes em arrays, enquanto o Pandas é focado em fornecer estruturas de dados flexíveis e ferramentas de análise de dados para trabalhar com dados estruturados. Embora haja alguma sobreposição de funcionalidades, o Pandas é mais adequado para manipulação e análise de dados, enquanto o NumPy está mais direcionado para cálculos numéricos e operações em arrays.
Exemplos:
Pandas:
No exemplo abaixo, utilizaremos a biblioteca Pandas para renomear uma coluna, utilizando a linguagem Python.
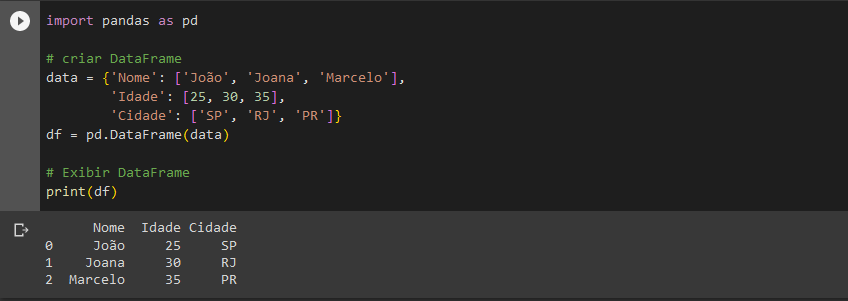
Na imagem 1, encontramos um problema, pois nas colunas “Cidades” estão escritas as siglas de estados.
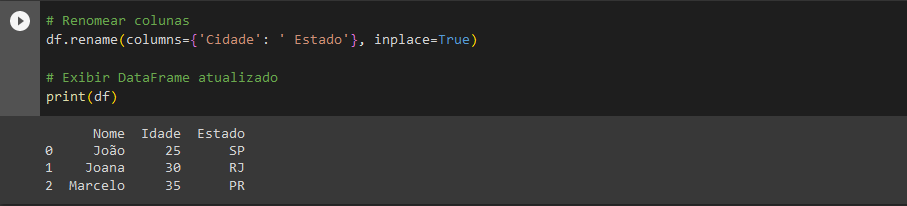
Assim, na imagem 2, o código atualiza “Cidades” para “Estados”.
Se você nunca teve contato com a linguagem, daremos uma breve explicação do que foi feito:
import pandas as pd
Essa linha importa a biblioteca Pandas e a renomeia como ‘pd’ para facilitar.
data = {‘Nome’: [‘João’, ‘Joana’, ‘Marcelo’], ‘Idade’: [25, 30, 35], ‘Cidade’: [‘SP’, ‘RJ’, ‘PR’]}
Aqui, estamos criando um dicionário chamado ‘data’ que contém informações sobre pessoas.
df = pd.DataFrame(data)
Essa linha transforma o dicionário ‘data’ em um DataFrame. Um DataFrame é uma estrutura de dados que organiza as informações em forma de tabela com colunas e linhas. Cada chave do dicionário se torna uma coluna no DataFrame, e os valores associados a cada chave são preenchidos nas linhas correspondentes.
print(df)
Essa linha imprime o DataFrame na saída do console, a tela que vemos.
NumPy
No próximo exemplo, utilizaremos a biblioteca NumPy para remover uma coluna.
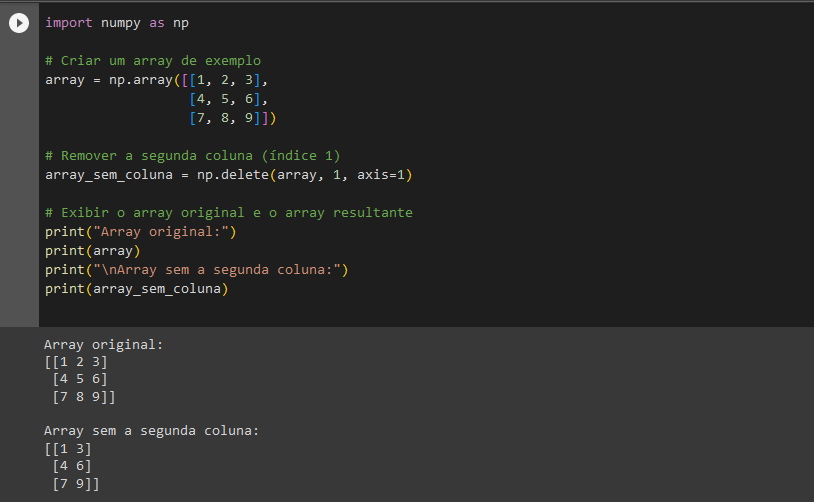
Mais uma vez, explicaremos o código:
Nesse código, a biblioteca NumPy é importada como ‘np’.
Um array bidimensional é criado com valores de 1 a 9, organizados em três linhas e três colunas. Em seguida, a segunda coluna desse array é removida usando a função ‘np.delete()’. O resultado da remoção é armazenado em uma variável chamada ‘array_sem_coluna’. Por fim, o código exibe o array original e o array resultante na saída usando a função ‘print()’.
Um array é semelhante a uma lista ( [1, 2, 3, 4, 5] ), mas otimizado para operações numéricas e matemáticas.
Outras Ferramentas
Outras ferramentas que podem ser usadas no processo de Data Munging ou Data Wrangling, incluem:
R: R é uma linguagem de programação especialmente projetada para computação estatística e análise de dados. Ela possui inúmeros pacotes, incluindo o dplyr e o tidyr, que oferecem recursos eficientes para manipulação de dados.
SQL: SQL (Structured Query Language) é uma linguagem de programação usada para gerenciar e manipular bancos de dados relacionais. É amplamente utilizado para consultas, extração e manipulação de dados em bancos de dados.
Excel: O Microsoft Excel é uma ferramenta amplamente utilizada para manipulação de dados. Ele oferece uma variedade de recursos para filtrar, classificar, formatar e transformar dados. Embora seja mais adequado para tarefas de menor escala, o Excel pode ser útil para tarefas básicas de limpeza e transformação de dados.
Qual a importância do Data Munging
Data Munging é importante porque nos ajuda a limpar, organizar e transformar dados brutos em um formato utilizável para análise. Ela garante a precisão dos dados, corrigindo erros e inconsistências, permitindo que tomemos decisões informadas.
Essa transformação de dados também nos permite combinar dados de diferentes fontes em um repositório central, como um Data Warehouse. Ela promove a consistência dos dados, facilitando comparações e análises, especialmente ao lidar com grandes conjuntos de dados ou várias fontes de dados.
Todo esse processo simplifica o processo de análise de dados, aprimora a qualidade dos dados, permite a integração de dados e melhora a precisão e a eficiência de análises.
Esse processo é útil para diversos profissionais, tais como cientistas de dados, analistas de dados, analistas de BI , pesquisadores e profissionais de áreas como marketing e vendas.
Como consequência, o Data Munging faz parte de um processo que auxilia empresas, organizações, tomadores de decisões e stakeholders a obterem insights mais precisos e significativos.
Vamos transformar a maneira como sua empresa processa seus dados?
Como você pode ver, o Data Munging é um processo complexo, mas essencial para qualquer empresa que deseja obter insights valiosos a partir de seus dados. Mas você não precisa fazer isso sozinho. A plataforma Kondado pode te ajudar a transformar seus dados brutos em informações acionáveis.
Se você está se sentindo sobrecarregado com a quantidade de dados que sua empresa está gerando, ou simplesmente não sabe por onde começar quando se trata de processamento de dados, nós podemos ajudar. Nossos serviços vão desde a integração de diferentes fontes até a transformação de dados, garantindo que você obtenha os insights mais precisos e significativos para a tomada de decisões.
Conclusão
O data munging, ou pré-processamento de dados, desempenha um papel crucial na preparação e transformação de dados brutos para análise. Ao limpar, corrigir e formatar os dados, garante-se a precisão e a consistência necessárias para obter insights confiáveis.
Esse processo simplifica a análise de dados, melhora a qualidade dos dados, permite a integração de diferentes fontes e aumenta a eficiência das análises. Profissionais de diversas áreas, como cientistas de dados e analistas de BI, se beneficiam do data munging, obtendo informações mais precisas e significativas para a tomada de decisões informadas.
Publicado em 2023-08-04