
Material de apoio:
1. Antes de iniciar esse tutorial, acesse a introdução da série de tutoriais clicando aqui, siga o passo a passo para usar a nossa plataforma interativa de SQL e pratique em tempo real
2. Participe do nosso canal do slack, onde você poderá tirar dúvidas sobre os tutoriais e também acessar conteúdo exclusivo do universo de dados, clicando aqui
Confira também os posts anteriores da série:
1. Introdução
2. Estrutura do SELECT
3. Filtrando valores com o WHERE
O comando GROUP BY é usado para agregar valores com base em suas semelhanças. Ele geralmente é usado junto de funções de agregação no SELECT, tais como:
| COUNT | Contagem |
| SUM | Soma |
| AVG | Média |
| MIN | Mínimo |
| MAX | Máximo |
A sintaxe básica do GROUP BY é a seguinte:
SELECT coluna1, SUM(coluna2)
FROM nome_tabela
WHERE coluna1 = condicao
GROUP BY coluna1 No código acima estamos fazendo uma soma da coluna2 e agrupando essa soma pela coluna1. Importante: Operações de agregação tais como as que expomos na tabela acima, não podem ser agrupadas no GROUP BY. Para exemplificar, vamos considerar a tabela "pessoas" da nossa base de dados de exemplo:
Usando o GROUP BY com COUNT
SELECT uf, COUNT(id)
FROM pessoas
GROUP BY ufNo código acima estamos contando quantos registros existem na tabela "pessoas" agrupados pelo campo uf:

Usando o GROUP BY com SUM
SELECT uf, SUM(idade)
FROM pessoas
GROUP BY ufJá no exemplo acima, estamos somando as idades de todas as pessoas, agrupando-as por UF:

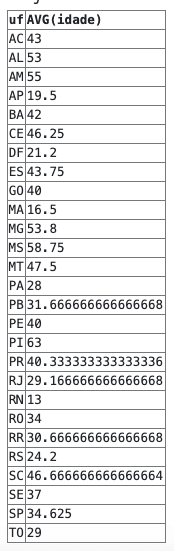
Usando o GROUP BY com AVG
SELECT uf, AVG(idade)
FROM pessoas
GROUP BY ufJá aqui estamos tirando a média da idade das pessoas, agrupadas por uf:
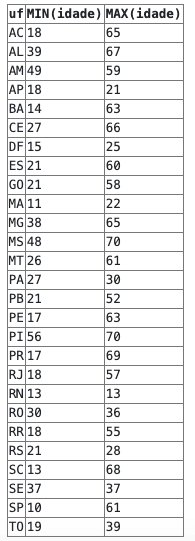
Usando o GROUP BY com MIN e MAX
SELECT uf, MIN(idade), MAX(idade)
FROM pessoas
GROUP BY ufJá neste exemplo, estamos extraindo a idade mínima e a máxima das pessoas que compartilham o mesmo UF:
Agrupando mais de uma coluna
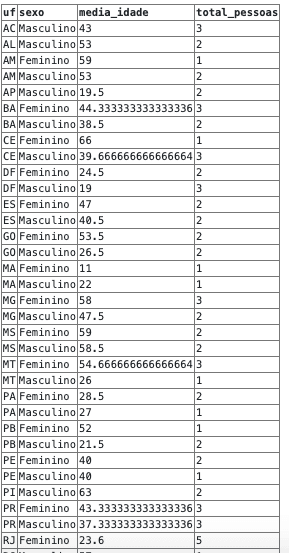
É possível agrupar mais de uma coluna no GROUP BY, inclusive com operações de agregação diferentes, como mostra o exemplo abaixo:
SELECT uf, sexo, avg(idade) AS media_idade, count(id) AS total_pessoas
FROM pessoas
GROUP BY uf, sexoNeste caso estamos extraindo a média de idade e contando quantas pessoas existem em cada grupo de UF e sexo, o resultado terá 1 linha para cada grupo composto. Por exemplo, no UF de valor BA existem pessoas do sexo feminino e masculino, portanto o estado fará parte de dois grupos: BA + Feminino e BA + Masculino:
Usando o HAVING para filtrar resultados após o GROUP BY
A cláusula HAVING é parecida com a cláusula WHERE, a diferença é que o HAVING é usado para filtrar valores após o GROUP BY. Para exemplificar:
SELECT uf, COUNT(id)
FROM pessoas
WHERE sexo = 'Masculino'
GROUP BY ufNo código acima estamos contando a quantidade de pessoas por UF, cujo sexo seja masculino:

Já no código abaixo, ao acrescentar o HAVING, estamos eliminando desse resultado todas as linhas cujo resultado do COUNT seja menor que 2 pessoas:
SELECT uf, COUNT(id)
FROM pessoas
WHERE sexo = 'Masculino'
GROUP BY uf
HAVING COUNT(*) >= 2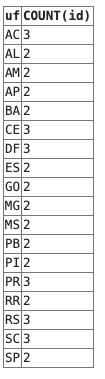
Como mostra a tabela de resultado acima, não aparecem no resultado todos os estados que tenham menos que duas pessoas.
Não deixe de conferir os post anteriores da nossa série de tutoriais, e fique de olho no nosso blog para acompanhar os próximos!
E para testar a plataforma Kondado gratuitamente por 14 dias, basta clicar no link abaixo:
Perguntas frequentes
GROUP BY pais, cidade). O resultado terá uma linha para cada combinação distinta dos valores dessas colunas.