A maneira mais rápida de fadar ao fracasso os seus esforços de data science, business intelligence e analytics é utilizar diretamente os dados que estão em produção para analisar informações.
As principais causas disso são:
- Formato: Os dados em produção possuem um formato voltado para as operações do produto, principalmente INSERT e UPDATE, que não é próprio para as consultas do tipo SELECT de analytics.
- Criticidade: As consultas de analytics envolvem operações de agregação e vários cruzamentos entre tabelas (JOIN) que, com muita frequência, são pesadas e afetam o desempenho do produto, podendo até “derrubar” o serviço para os usuários, causando uma péssima experiência do cliente e desespero dos SREs e DevOps
- Análises rasas: você estará consultando sempre apenas uma fonte de dados, ou se enganando com emparelhamento ao invés de cruzamento de dados de outros serviços utilizados (como Zendesk, Adwords ou Pagar.me)
ETL: Extract, Tranform, Load
O conceito de ETL surgiu como uma forma de eliminar essas falhas. A sigla, em inglês, significa Extract, Transform, Load. Quer dizer:
Uma operação de ETL extrai os dados da origem (a fonte de produção), aplica alguma transformação (formata os dados para consultas) e carrega em uma outra base de dados (destino), apartada da produção, que será utilizada apenas para analytics
O ETL consegue sanar as principais causas de fracasso dos seus esforços de analytics, pois já deixa os dados em um formato definido para consultas, disponibiliza uma outra base de dados para consultas de analytics e várias fontes de dados podem ser integradas no destino final, abrindo caminho para poderosos cruzamentos de dados.
Entretanto, ele traz outros problemas, principalmente porque eleva bastante a complexidade das operações de dados, sendo necessário certo esforço de desenvolvimento para colocar em prática essa integração de dados das fontes para o destino de dados.
Uma vez operacional, os fluxos de ETL tornam-se também complexos de serem gerenciados, sendo necessário mais esforços de pessoas especializadas caso seja necessário alguma alteração.
Por exemplo, vamos supor que no seu produto, há uma tabela de cadastro dos usuários e o seu objetivo é saber o número de usuários atuais do produto. Um ETL simples irá criar no destino uma tabela com apenas uma variável, que é o número de usuários atual e atualizar esse valor de acordo com alguma frequência.
Passado certo tempo, você vê a necessidade de não apenas contar os usuários, mas entender a evolução deles ao longo do tempo. Ou seja: a parte de transformação do seu ETL, que antes apenas contava os registros da fonte, agora precisa contar os registros agrupados de acordo com a data de criação. Para fazer essa alteração, o desenvolvedor da integração precisará alterar o código do ETL, o que pode levar certo tempo para ser feito.
Os projetos de dados bem sucedidos são bastante dinâmicos e precisam sempre de mais ou menos informações, fazendo com que esse fluxo de ETL precise ser alterado diversas vezes e sobrecarregando o desenvolvedor de integração.
Esse problema é frequente por causa do skillset diferente de cada participante de um projeto de dados. O desenvolvedor de integração é um programador que domina a linguagem de programação que usou para criar o ETL e o consumidor de dados é um analista/cientista de dados que domina SQL ou ferramentas de visualização e é mais voltado para entender as necessidades do negócio e explorar dados, tendo grande necessidade de lidar com TODO o universo de dados disponível.
ELT: Extract, Load THEN Transform
Para evitar esse vai e volta, surgiu o conceito do ELT, que altera um pouco o ETL, fazendo primeiro a carga dos dados no destino e depois a transformação. Isso quer dizer que, enquanto o ETL coloca apenas dados já tratados no destino (e precisa de um desenvolvedor para alterar o processo), o ELT replica os dados brutos da fonte para o destino e deixa nas mãos dos analistas e cientistas de dados para que apliquem as transformações que acharem necessárias, conforme forem vendo as necessidade do negócio e dos seus algoritmos.
Obviamente, o ELT requer mais recursos do destino de dados, já que agora é lá que são realizadas as transformações de dados. Entretanto, hoje o poder dos destinos de dados disponíveis torna o ELT uma opção mais simples e ágil ao ETL e a escolha perfeita para as áreas de dados mais dinâmicas.
Como a Kondado lida com isso?
A plataforma da Kondado foi pensada para tornar os processos de dados simples e intuitivos, por isso optamos por implementar o ELT em escala.
O primeiro passo para isso foi simplificar a parte de leitura de dados. Antes você precisava deslocar algum engenheiro do seu time de produto ou mesmo contratar um desenvolvedor apenas para integração de dados. Com a Kondado, qualquer pessoa pode criar uma integração, sem precisar digitar uma linha de código:

Uma vez no destino, os dados podem ser transformados com o uso da nossa funcionalidade de Modelos:
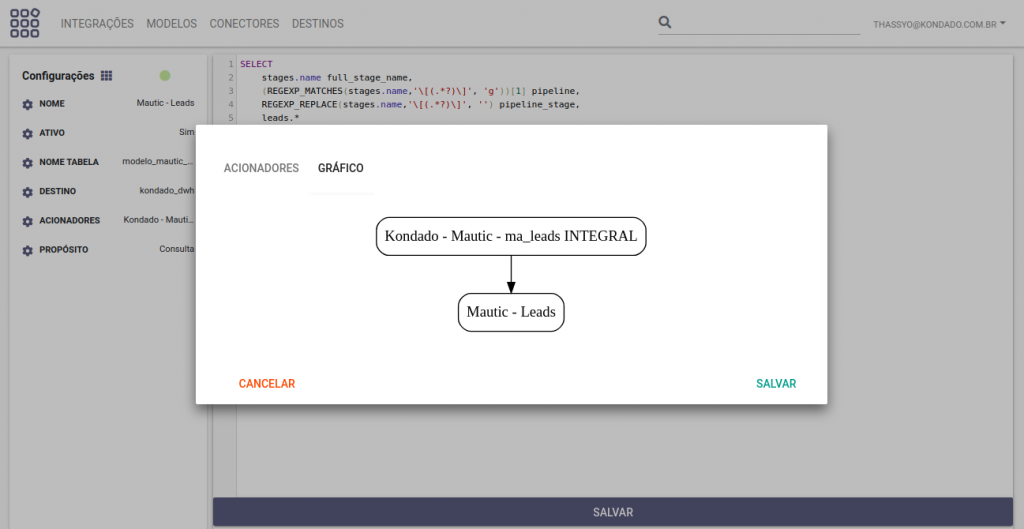
Os modelos são acionados por integrações (ou outros modelos) e materializam as transformações em tabelas no destino de dados (garantindo a performance da consulta final) e fazendo com que, sempre que novos dados chegarem ao seu destino, eles já passem pela sua transformação.
Qualquer cientista ou analista de dados pode criar um modelo, porque eles são definidos VIA SQL, de acordo com a sintaxe do seu destino de dados. Nesse tutorial explicamos como criar modelos na plataforma Kondado.
Além de deixar bem orquestrado o seu fluxo de dados, também facilitamos a sua organização, pois os metadados de integrações e modelos (como nomes de tabelas, SQLs e nomes de colunas) são facilmente consultáveis na nossa plataforma, facilitando a rastreabilidade dos seus dados.
Publicado em 2020-03-10