O Google Cloud Storage é um serviço para armazenamento de objetos e arquivos (por exemplo CSV e JSON) no Google Cloud.
Ao adicionar o conector do Google Cloud Storage na Kondado, você poderá criar ETLs dos seus arquivos diretamente para o seu Data Warehouse ou Data Lake com apenas alguns cliques.
Adicionando o conector
Para adicionar o conecto do Google Cloud Storage, siga os passos abaixo:
1) Acesse a sua conta do Google Cloud
2) Clique neste link para acessar a seção de Service Accounts, ou siga a imagem abaixo:
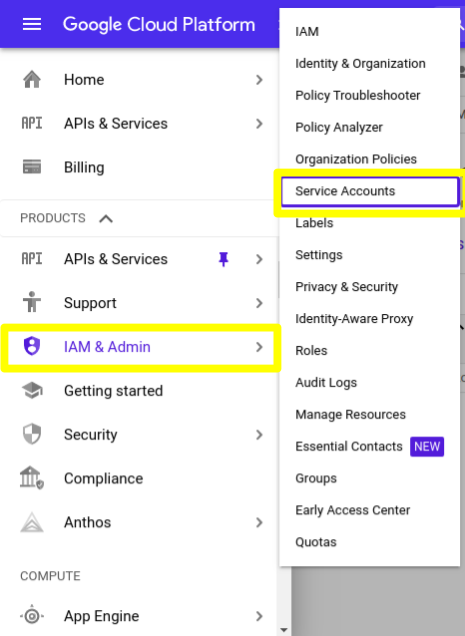
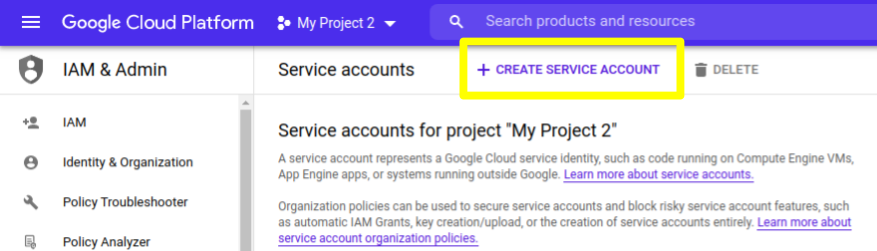
3) Uma vez na seção de Service Accounts, clique em “CREATE SERVICE ACCOUNT”
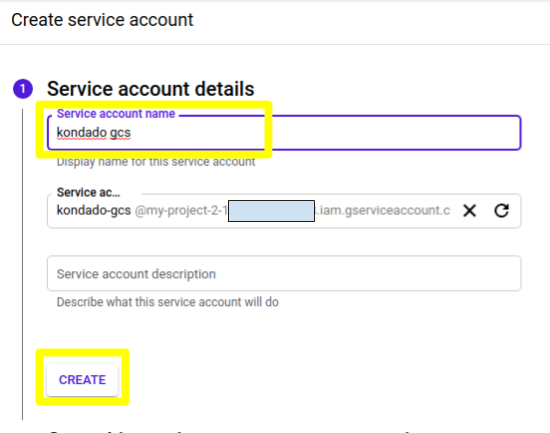
4) No primeiro passo, preencha um nome para a sua service account (por exemplo, “kondado gcs”) e clique em “CREATE”
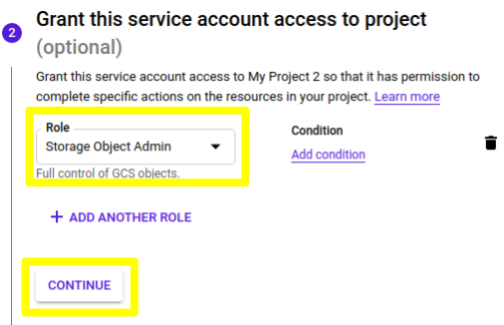
5) No segundo passo do processo de criação, selecione o Role “Storage Object Admin” e clique em CONTINUE
6) Agora basta clicar em “DONE” para finalizar a criação
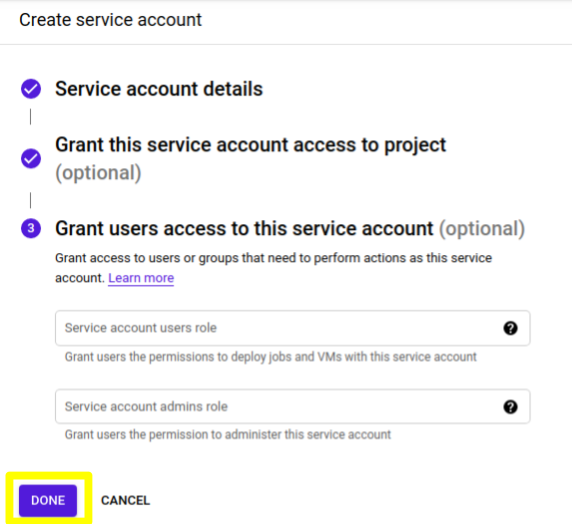
7) Uma vez criada, você será direcionado para uma lista de todas as service accounts ativas. Localize a que você acabou de criar e, nos três pontos verticais à direita, clique em “Create key”
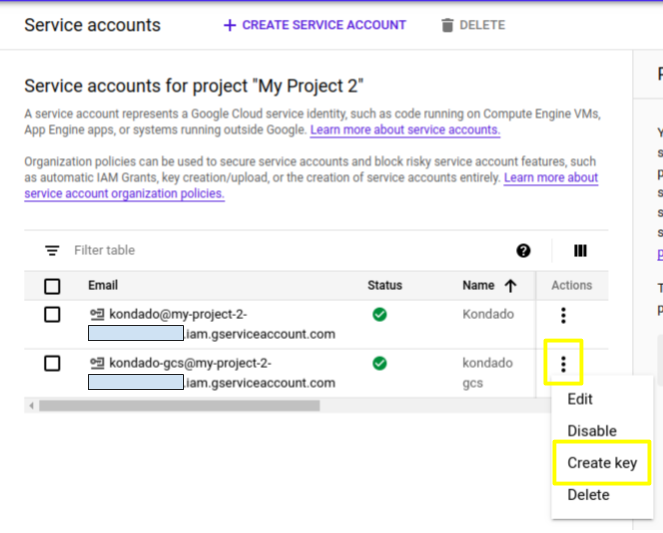
8) No diálogo, selecione o tipo “JSON” e depois clique em “CREATE”

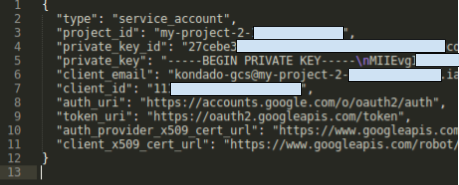
9) Após clicar em criar, a chave será baixada no seu computador. Abra o arquivo que fez download em um editor de texto, ele terá um formato parecido com este:
10) Faça login na Kondado, vá para a página de adicionar conectores e selecione o conector do Google Cloud Storage
11) Na página de adição do conector, faça o seguinte:
- Em “Bucket” preencha o nome do seu bucket
- Em “Credencial JSON”, copie e cole os valores do arquivo do passo (9)

12) Agora basta clicar em “SALVAR” e você estará pronto para enviar seus arquivos do Google Cloud Storage para o seu Data Warehouse ou Data Lake
Integrações
Gráfico de relacionamento entre tabelas

CSV
Você poderá indicar o nome de um arquivo ou mesmo o início do nome do arquivo e iremos integrar todos eles.
Uma vez executada, a integração irá guardar a maior data de alteração dos arquivos que leu e, na próxima execução, buscar apenas arquivos que possuem data de alteração posterior.
Para poder absorver arquivos com colunas diferentes, os dados serão pivotados no destino e seguirão o seguinte padrão:
| Campo | Tipo | |
|---|---|---|
row_number |
int |
|
column_number |
int |
|
first_column_value |
text |
|
value |
text |
|
__file_basename |
text |
|
__file_path |
text |
|
__file_name |
text |
|
__kdd_insert_time |
timestamp |