O nosso destino do S3 (Simple Storage Service) da AWS permite que você crie um data lake de forma simples e barata seguindo o conceito de separar o armazenamento do processamento, comum em bancos de dados.
Ao criar o S3 como destino na Kondado, você pode realizar ETL (ou ELT) de dados de mais de 70 fontes: https://kondado.com.br/conectores.html e utilizar tecnologias de virtualização como presto, athena, dremio e Redshift Spectrum para realizar consultas nos seus dados.
Como no S3 há uma separação entre processamento e armazenamento, os nossos modelos não se aplicam a este destino. Além disso, as operações de agregação de dados e desduplicação (UPSERT) devem ser feitas por você, seja na camada de virtualização ou com scripts como o AWS Glue. Para ajudá-lo neste processo, nós adicionamos neste destino a possibilidade de você enviar notificações para URLs que irão disparar estes processos.
Abaixo nós iremos explicar detalhadamente como funciona o nosso destino S3 e como adicioná-lo na Kondado.
1. Criação da chave de acesso
O primeiro passo para adicionar o S3 como destino é a criação de uma chave de acesso na AWS para utilização da Kondado. Você pode acompanhar neste tutorial da AWS como fazê-lo.
A access key criada, deve ter as seguintes permissões:
- s3:PutObject
- s3:GetObject
- s3:ListBucket
- s3:DeleteObject
Além disso, você deve criar um bucket onde os dados serão armazenados.
Você pode utilizar a política abaixo como exemplo para dar acesso a um bucket específico. Lembre-se de editar a variável “CHANGE-THIS-WITH-BUCKET-NAME” com o nome do seu bucket de fato
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "kondadorecommendeds3destpolicy20220111",
"Effect": "Allow",
"Action": [
"s3:AbortMultipartUpload",
"s3:DeleteObject",
"s3:ListMultipartUploadParts",
"s3:PutObject",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::CHANGE-THIS-WITH-BUCKET-NAME/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket",
"s3:ListBucketMultipartUploads"
],
"Resource": [
"arn:aws:s3:::CHANGE-THIS-WITH-BUCKET-NAME"
]
}
]
}Caso o seu bucket utilize criptografia, também é necessário dar ao IAM permissão para acessar a KMS key: Veja mais neste tutorial da AWS
De posse da access key e do bucket, você já pode preencher as primeiras informações de criação do destino
- Em Id da chave e Segredo da chave, preencha as informações da chave gerada anteriormente
- Em Bucket preencha apenas o nome do seu bucket já existente, sem nenhuma formatação de URL. Por exemplo “meu-bucket” está correto e “
s3://meu-bucket” está errado. Lembre-se também de utilizar apenas o nome raíz do bucket, sem pastas filhas. Por exemplo, “meu-bucket/minha-pasta” está errado – caso queira colocar uma pasta adiciona, faça isso ao preencher o nome da tabela na integração
2. Formato do arquivo de saída
Atualmente, enviamos arquivos nos seguintes formatos:
2.1 JSON (jsonl)
Este formato salva dados no formato JSON, um em cada linha do arquivo, com aspas escapadas por \. Este é um exemplo de um arquivo jsonl que será enviado para o seu data lake:
{"\"keyword\"":"y","\"url\"":"https:\/\/mailchi.mp\/a37895aff5ac\/subscribe_newsletter","\"title\"":"https:\/\/mailchi.mp\/a37895aff5ac\/subscribe_newsletter","\"timestamp\"":1572559835000,"\"clicks\"":1}
{"\"keyword\"":"z","\"url\"":"https:\/\/pipedrivewebforms.com\/form\/43fd725e54683d565a44ed4872c3560f4639452","\"title\"":"Kondado - contato","\"timestamp\"":1572560617000,"\"clicks\"":2}Caso você não aplique compressão, os arquivos serão salvos com a extensão “.json”
2.2 CSV
O formato CSV irá salvar arquivos neste formato tradicional e com extensão “.csv” caso você não tenha fornecido nenhum método de compressão. Você precisará fornecer alguns parâmetros adicionais de formatação do arquivo:
2.2.1 Delimitador de colunas
Os valores possíveis para o delimitador de colunas são
- Vírgula (“,”)
- Pipe (“|”)
- Tab (“\t”)
2.2.2 Quote
O parâmetro quote indica como cada coluna em uma linha do arquivo será envolta em aspas. As opções possíveis são um mapeamento 1 x 1 com o módulo CSV do python
- All
- Minimal
- Non-numeric
- None
Recomendamos o formato “All”.
Como você deve ter percebido, quote e o delimitador de colunas podem entrar em conflito com o seu conteúdo caso estes caracteres também estejam presentes nos valores. Então, todos os arquivos salvos possuem um caracter de escape padrão para valores conflitantes, o backslash (“\”).
2.2.3 Cabeçalho
Você também pode escolher se deseja que os arquivos enviados venham com cabeçalho ou não. Lembrando que, se você cadastrar uma URL de notificações, o envio de cabeçalho torna-se desnecessário, pois nós enviaremos para você o schema do objeto, com a ordem das colunas de acordo como foram escritas no arquivo. A ordem das colunas também obedecerá a mesma ordem de exibição da nossa UI quando você clica em “DETALHES” de uma dada integração.
2.3 Parquet
Este formato salva dados no formato parquet.
Caso você não aplique compressão, os arquivos serão salvos com a extensão “.parquet”
3. Compressão
Você pode escolher aplicar um método de compressão aos seus arquivos ou não. Os métodos de compressão disponíveis irão alterar a extensão dos arquivos salvos.
3.1 GZIP
Os arquivos comprimidos com o método gzip irão receber a extensão “.gz”
4. URL de notificação
Caso o parâmetro “Notificar alguma URL” seja preenchido, você precisará informar uma URL válida em “URL para notificações”. Esta URL deve estar habilitada para receber posts.
4.1 Quando ocorrerá a notificação na URL?
Ao fim de uma integração, para cada objeto integrado e para cada operação, nós faremos um post na URL informada:
- “para cada objeto” significa que integrações que populem mais de uma tabela farão uma notificação por tabela
- “para cada operação” significa que as operações de envio para as tabelas full e para as tabelas de deltas (caso você tenha escolhido por manter deltas) farão notificações separadas
4.2 E se a URL falhar?
Iremos considerar como sucesso uma notificação para a URL informada que retorne um código de resposta 200 em até 30 segundos. Caso a resposta seja diferente disto ou demore mais, iremos realizar mais 3 tentativas e apontar um erro na integração caso a falha persista. Entretanto, os arquivos nas pastas/prefixos full e deltas não serão apagados
4.3 Payload enviado
Com os dados que serão enviados para a sua URL de notificação, você terá todas as informações necessárias para disparar processos posteriores para manipulação dos arquivos enviados. Os campos padrões do JSON de payload são os seguintes:
4.3.1 pipeline_id
Id da integração que gerou os arquivos. O id de uma integração pode ser obtido através da URL da integração da Kondado no seu navegador: https://app.kondado.com.br/pipelines/id_da_integracao
Exemplo:
"pipeline_id":231923
4.3.2 bucket
Bucket onde os arquivos foram enviados. Corresponde ao bucket cadastrado por você nos parâmetros do destino no momento em que a integração salvou os arquivos
Exemplo:
"bucket":"my-kdd-data-lake"
4.3.3 kdd_operation
Operação que disparou a notificação. Os valores possíveis são:
- merge_deltas: indica que esta operação significa um envio de dados para a tabela de deltas
- merge_full: indica que esta operação significa um envio de dados para a tabela full
Exemplo:
"kdd_operation":"merge_deltas"
4.3.4 kdd_replication_type
O tipo de replicação desta integração (integral/incremental). Para integrações incrementais, você deve fazer “upsert” dos valores dos arquivos com o seu arquivo principal. Para integrações integrais, os novos arquivos enviados devem substituir o arquivo principal anterior.
Os valores possíveis deste parâmetro são:
- drop: indica que a integração é do tipo integral
- savepoint: indica que a integração é do tipo incremental
Este parâmetro é enviado apenas quando kdd_operation=merge_full.
Exemplo:
"kdd_replication_type":"savepoint"
4.3.5 kdd_replication_keys
Caso a sua integração seja incremental (kdd_replication_type=savepoint), então este campo irá conter os campos (separados por vírgula) que você deverá utilizar para fazer upsert com o arquivo principal.
Exemplo:
"kdd_replication_keys":"lead_email,campaign_id"
4.3.6 schema
Array de jsons com os campos enviados para os arquivos, na ordem em que aparecem (útil para CSV e também para que o seu arquivo agregador principal tenha uma tipagem condizente com os seus dados).
Neste array, cada json corresponderá a um campo no arquivo de destino e conterá as seguintes informações:
- db_name: nome do campo no destino. Este é o valor que você deve utilizar para criar o seu arquivo principal
- type: tipagem do campo, conforme normalização da Kondado. Os tipos de campos que são atualmente suportados por este destino são:
- text
- timestamp
- date
- float
- int
- boolean
- time
- key: nome do campo conforme conector/CMS da Kondado. Para fins de agregação dos arquivos em um arquivo principal, este campo pode ser ignorado, estamos enviando-o apenas para fins de esclarecimento
Exemplo:
"schema":[
{
"db_name":"lead_id",
"type":"text",
"key":"id"
},
{
"db_name":"etapa",
"type":"text",
"key":"Etapas__PerguntasRespostas->Etapa"
},
{
"db_name":"pergunta",
"type":"text",
"key":"Etapas__PerguntasRespostas->Pergunta"
}
]
4.3.7 files
Array com os nomes arquivos disponibilizados e a sua localização (prefixo). Por exemplo:
"files":[
"page_hits_deltas/20201030220519913118.gz",
"page_hits_deltas/20201030220533013600.gz"
]
4.3.8 file_format
Formato do arquivo final criado. Lembre-se que, caso o arquivo sofra compressão, o formato não corresponderá à sua extensão, mas o arquivo “dentro” do arquivo comprimido estará neste formato. Exemplo:
"file_format":"json"
4.3.9 file_format_params
Caso o formato de arquivo selecionado requeira parâmetros adicionais de formatação (por exemplo, CSV) este campo irá trazer um JSON com os parâmetros utilizados para criar o arquivo.
Exemplo (CSV):
"file_format_params":{
"csv_delimiter":"pipe",
"csv_quote":"all",
"csv_include_header":"yes"
}
4.3.10 file_compression
Este parâmetro indica a compressão aplicada ao arquivo de saída. Caso nenhuma compressão tenha sido aplicada, o seu valor será “no”.
Exemplo:
"file_compression":"gzip"
4.3.11 kdd_row_count
Este parâmetro indica quantos registros/linhas há no total nos arquivos enviados.
Exemplo:
"kdd_row_count":29173
5. Prefixo
Caso o parâmetro “Incluir prefixo no nome do arquivo?” seja preenchido, você deverá incluir um texto que irá ser inserido no início do nome do arquivo a ser enviado. Este texto pode conter caracteres de formatação que possam ajudar a particionar os arquivos em pastas no S3 (exemplo).
O nome/parte final do arquivo, sempre será a timestamp em que foi executada a integração + extensão, neste formato: [YYYYMMDDhhmmssfffff] [.] [extensão]
Além deste nome fixo, com este parâmetro de prefixo, você pode adicionar variáveis que ajudarão a organizar o seu bucket, são eles:
- [exec_year]: Ano (YYYY) da execução da integração
- [exec_month]: Mês (MM) da execução da integração
- [exec_day]: Dia do mês (DD) da execução da integração
- [exec_hour]: Hora (hh 24) da execução da integração
- [exec_minute]: Minuto (mm) da execução da integração
- [exec_second]: Segundos (ss) da execução da integração
- [exec_millisec]: Milisegundos (fffffff) da execução da integração
Estas variáveis podem ser combinadas com texto livres e serão concatenadas na frente do nome do arquivo durante a inserção no S3.
Atenção: É necessário que sejam escritos os colchetes – ] e [
Exemplo
Considere que foi preenchido o seguinte prefixo:
[exec_year]/month=[exec_month]/{day=[exec_day]}/
Sendo o nome final do arquivo este:
20210922161050851020.json
Neste caso, o nome a ser escrito na tabela do destino será:
2021/month=09/{day=22}/20210922161050851020.json
Perceba que foi utilizado uma barra “/” no final do prefixo ([exec_year]/month=[exec_month]/{day=[exec_day]}/) – caso essa barra não fosse inserida, o arquivo seria 2021/month=09/{day=22}20210922161050851020.json, que pode não ser o que você deseja
6. Formato de data
Para colunas do tipo date e timestamp, é possível especificar o formato de datas:
- ISO: os valores serão escritos no formato ISO 8601
- Epoch: Os valores serão escritos no formato unix epoch time, em segundos
Questões gerais
Tabelas ou pastas ou prefixos?
Quando enviamos para outros bancos de dados, chamamos os “conjuntos” de registros de tabelas. No caso do S3, a forma de reunir os registros que pertencem à mesma categoria é por prefixos (comumente chamados de “pastas”). Para manter a uniformidade com o restante de destinos que suportamos, continuaremos a chamar de tabelas estes conjuntos de registros. Desta forma, sempre que você ver “tabela” dentro da Kondado referindo-se ao destino S3, entenda como “prefixo” (ou “pasta”). Então, ao dar o nome a uma “tabela full” você estará dizendo qual deve ser o prefixo (pasta) dos arquivos criados no modo “full”
Caso deseje, você pode utilizar “/” nos nomes das tabelas para criar uma estrutura de subpastas
As tabelas/pastas são a parte “fixa” da inserção dos arquivos, quer dizer, os arquivos sempre serão enviados para o mesmo caminho bucket/pasta. A criação de “sub-pastas” com o parâmetro de prefixo premite maior dinamismo, sendo possível especificar pastas para anos, meses, dias, horários, etc diferentes, que serão alterados conforme o momento de execução da integração.
Com todas as variáveis que influenciam o nome e caminho do arquivo, você pode se guiar pelo diagrama abaixo que representa seus componentes e onde podem ser configurados
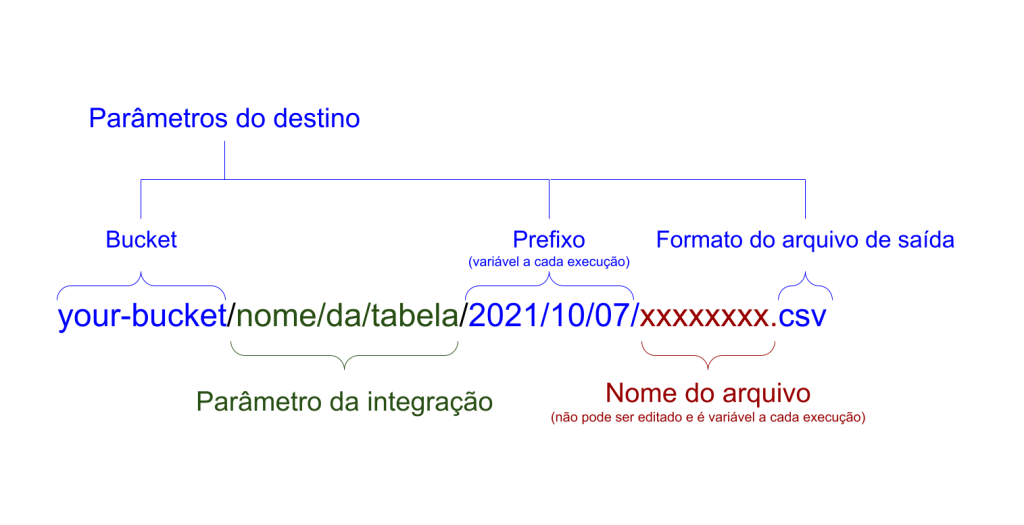
Fluxo de criação de arquivos de uma integração
Ao olhar o seu bucket no S3, você irá se deparar com várias “pastas” que possuem uma nomenclatura similar a esta “kdd_xxxxxxx_staging”. Os arquivos com este prefixo estão atualmente sendo integrados pela Kondado. Uma vez que a leitura de dados da fonte termine, estas pastas de “staging” irão conter todos os arquivos desta execução. A Kondado, então, irá realizar a cópia destes arquivos para as tabelas full e deltas – ao fim desta cópia, iremos disparar a notificação para a URL cadastrada.
Antes e depois de cada integração, as tabelas de staging serão esvaziadas para receber novos arquivos. Então, pedimos para que não apague estas tabelas de staging, pois a sua integração poderá falhar ou, pior, gerar dados incompletos.
Na Kondado, quando um destino é um banco de dados, nossa plataforma lida com toda a de-duplicação dos dados a cada atualização e chegada de dados novos. Entretanto no caso do S3, o este fluxo é de responsabilidade do usuário utilizando os campos de replication_keys. Caso não utilize URL de notificação, estes campos de replicação podem ser encontrados na documentação do conector, ao acessar o gráfico de relacionamento. Eles estarão marcados com um círculo ao lado do campo. Em raros casos, é possível que dois arquivos semelhantes sejam enviados em uma mesma execução, por isso o seu fluxo de de-duplicação deve conseguir lidar com isso ao verificar os novos arquivos para de-duplicação